

Next: リソース内容の評価方法
Up: 内容を考慮した収集方法
Previous: 内容を考慮した収集方法
リソース収集は基本的に、以下に示すリソースの内容を考慮した、WWWページへの
重み付けによる方法で行う。
ただし、重み( 収集の優先順位 )が同じであった場合には、幅優先探索
 を使用して行う。
を使用して行う。
位置情報を含むリソースを選択的に収集するためには、既に収集したWWWページ
中に含まれるハイパーリンク(アンカー)から収集すべきものを予測および選択す
る必要がある。
そこで次のような実験を行った。
- サンプルページ( WWW上からランダムに選択した20ページ )に含まれる位
置情報を抽出し、位置情報の現れ方により分類する。
- サンプルページ中に含まれるアンカーについて、アンカーラベル中の位
置情報の有無による分類を行い、更に、リンク先ページの位置情報の有
無を調べる。
- 各分類毎に、位置情報を含むWWWページの割合( = 位置情報含有率) を求
める。
実験結果を図 に示す。
に示す。
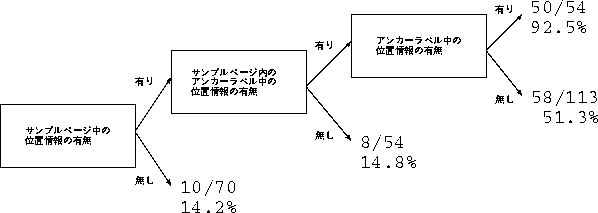
図: 位置情報の現れ方によるリンク先ページの位置情報含有率
図中の上段の数字の分母は、条件にあてはまる全アンカー
数を示し、分子はそのうちリンク先のページが位置情報を含むものの数を示して
いる。
下段の数値は、位置情報含有率である。
実験の結果、アンカーラベルに着目することで、WWWページを収集せずに内容の
推測が可能であることが分かった。
この実験を基に、以下に示す、未収集のWWWページに対する重み付けのアルゴリ
ズムを提案する。
- アンカーラベルを形態素解析し、地名やランドマークの情報を含
むものの重みを大きくする。
- ただし、抽出元のページに位置情報を含むアンカーラベルがある場合は、
そのページに含まれる未収集のWWWページに対しする重みは変更しない。
どちらにもあてはまらない場合は、WWWページの重みを下げる。
更に正確な収集を行うために、位置情報検索システム用ロボットでは、既に収集
したWWWページに対する重み付けも行う。
この重み付けは2回目以降の収集に有効である。
この場合、WWWページは既に収集済みで、位置情報抽出には、WWWページの内容を
使用できるため、上記の抽出に加え、電話番号や郵便番号等の抽出を行うことで、
より正確な位置情報抽出を行う。
これらの重み付けの様子を図に示す。
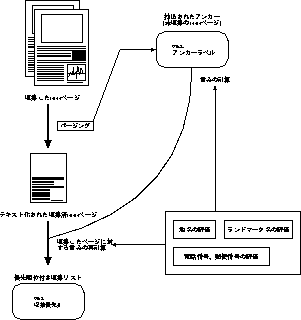
図: WWWページに対する重み付け
Nobuyuki Miura
Fri May 1 22:48:41 JST 1998